芯片六巨头,决战手机AI芯片光明顶

智东西
作者 | 云鹏
编辑 | 心缘
手机AI芯片大战,正成为今天科技赛场上极为重要的一场较量。
从手机芯片大厂到手机终端巨头,无一不在力挺端侧AI,不论是系统级还是个性化AI的实现,都离不开AI的端侧计算,而计算就离不开芯片。
尤其结合当下AI智能体、AI OS方向成为行业共识,AI对芯片能力的需求愈发高涨,这种需求不是简单的“TOPS”算力,而是对芯片全方位能力的考验。
放眼国内,小米掏出自研SoC大招,玄戒O1首秀即在CPU、GPU性能方面与高通联发科掰手腕,与苹果A18 Pro较量互有胜负。据小米方面透露,其自研NPU架构也实现了不少细节创新。

▲5月22日小米发布玄戒O1自研芯片
华为海思的麒麟手机芯片虽仍然受限于工艺制程,却在架构和软件系统层面寻找突破口,自研泰山大小核彻底摆脱Arm架构,基于自研鸿蒙操作系统的深度优化连年实现整机性能的提升,AI功能落地速度甚至部分超过安卓旗舰机。

▲6月20日华为开发者大会(HDC)上展示的最新手机端侧AI功能,AI可以帮助用户在拍照时进行辅助构图
放眼全球,苹果芯片在硬件性能方面已经遇到不少有力挑战者,在AI掉队之下,如何基于芯片和系统优势实现AI体验是苹果当务之急;三星3nm工艺被曝良率堪忧,自家Exynos旗舰芯迟迟未能量产落地,内部团队动荡,但其多年技术积累令其仍然是AI手机时代不可忽视的一股芯片力量。
在终端大厂加码布局自研芯片之时,高通、联发科自然也感受到了压力,高通自研Oryon架构CPU进一步实现能效比的提升,联发科连放AI开发工具大招力求用完善生态吸引AI开发者。

▲2024年10月21日高通发布采用Oryon CPU的旗舰SoC骁龙8 Elite
纵观行业,虽说做手机不一定是“得芯片者得天下”,但在AI手机时代强化对芯片技术的掌控,已悄然成为巨头们的必然选择。
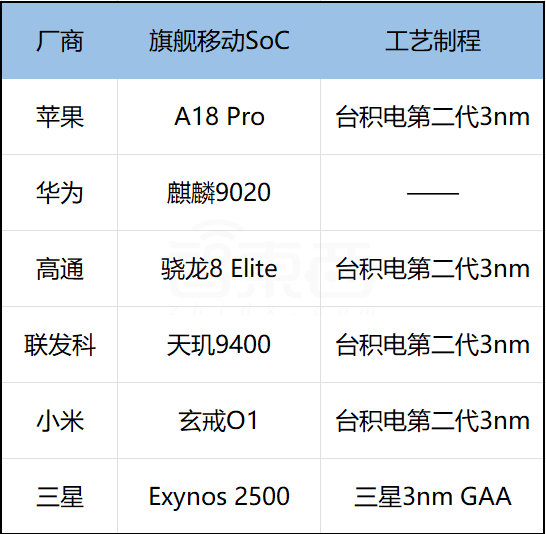
▲六大主流手机AI芯片厂商旗舰SoC及工艺情况
从工艺制程到芯片架构,再到基于芯片的AI开发生态,如今各家有哪些关键动作和布局,又有哪些台上台下的精彩较量?我们尝试在这场AI芯片手机大战中洞察到更多关键趋势。
一、2nm被苹果抢先包圆,小米高通联发科们要靠什么打赢“能效比”?
为何芯片对AI手机的体验如此重要?性能和功耗表现可以说是一切功能想要真正落地前都必须要迈过的一道坎。
对于移动智能设备来说,PPT中漂亮AI功能的实现,前提都是不能以牺牲手机功耗、续航为基础,这是一条绝对的“红线”。
十几年来,提升芯片能效一直是智能手机芯片行业迭代的重点,而在AI手机时代,这一需求显得更为迫切。
从工艺制程到芯片架构设计,各家的竞争态势愈发激烈。
工艺方面,如今旗舰手机SoC的工艺制程已经普遍来到了第二代3nm阶段,包括苹果、高通、联发科、小米。当然,苹果每年都会率先包圆台积电最新最强的工艺,比如明年的2nm。
苹果分析师Jeff Pu提到,A19 Pro芯片会采用台积电第三代3nm制程,苹果最快会在明年的iPhone 18系列上引入台积电2nm工艺。

台积电董事长魏哲家在财报电话会上曾透露,台积电宝山厂首批2nm产能已经全部被苹果包圆了。
高通、联发科、小米虽然不是第一批,但目前的旗舰芯片也都用上了苹果“同款”工艺,三星这边虽然自家集团中的半导体部门有着先进工艺制程技术,但在量产和内部管理方面却频频“翻车”,甚至原计划的3nm Exynos系列芯片直接难产。
就在最近,三星的芯片业务被曝出伪造数据、掩盖缺陷的丑闻,据报道,三星芯片工程师也纷纷跳槽到对家,可以说是“屋漏偏逢连夜雨”。
相比三星工艺翻车,华为海思这边则是承压前行,由于代工受到限制,麒麟手机芯片无法用上最新工艺制程,在芯片能效比提升方面与同代采用新工艺的旗舰芯片会拉开一定差距,操作系统和软件层面的优化对整机性能提升贡献较大。
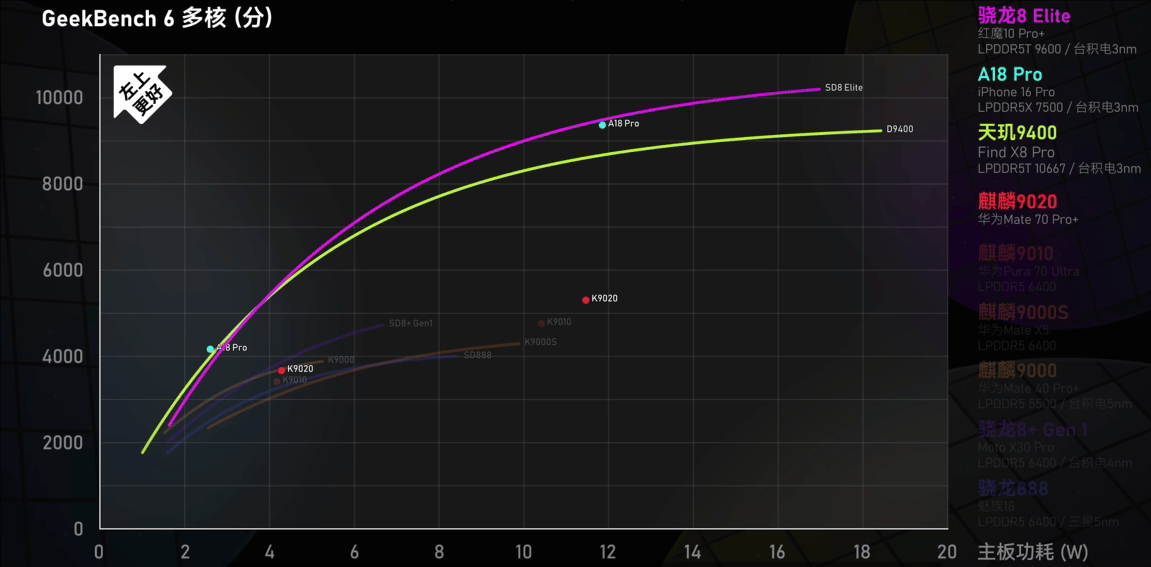
▲ CPU多核能效曲线(红色圆点为麒麟9020,紫色、绿色曲线为高通、联发科旗舰芯,时间为2024年12月),来源:极客湾Geekerwan
整体来看,工艺制程的升级对芯片能效的提升固然十分重要,但工艺制程的进步在明显放缓,手机能效比如果想要实现颠覆性提升,不能仅凭工艺升级。
台积电在2024年的IEDM会议上提到,同面积2nm芯片的晶体管数量比3nm芯片多15%,同功耗下芯片性能提升大约15%。
在工艺之外,芯片设计层面、架构层面等更多厂商可自主把控环节的技术创新就显得更为重要,这也是各家能够形成差异的一部分。
二、巨头死磕自研架构,芯片设计掀起“真假自研大战”
业内普遍认为,在做AI手机这事上,苹果有着软硬件打通的先天优势——越深度全面地掌握底层技术,就越容易最终实现整机更好的体验。
各家手机AI芯片的自研深度或许决定着其AI手机体验的上限天花板。
虽然自研芯片的优势不是绝对的,但强化对自研芯片技术的掌握,已经成为目前手机芯片领域毋庸置疑的大势所趋。
具体来看,各家手机AI芯片自研模式有所不同,苹果、华为、高通,基于Arm指令集,在SoC所有核心模块实现自研;联发科、小米、三星,基于Arm指令集,采用Arm公版架构+部分模块自研。
当然,不论是哪种模式,都是毫无疑问的“自研”。简单来说,Arm指令集就像是芯片说的“语言”,但两个人即便都用同样的语言来写文章,也会有“大学生论文”和“小学生作文”的差别。
苹果这边的自研深度自然不必多说,甚至可以说是“断档式领先”。
深度自研在AI方面实则能带来不少优势,比如苹果芯片的GPU模块可以针对图形处理和AI计算进行优化,其神经网络引擎(NPU)更是苹果独特优势,对端侧AI各类功能加速都进行了深度优化。

华为虽然芯片工艺受限,但麒麟芯片的架构却一直在持续迭代。据了解,在最新的麒麟9020这一代上,华为已经实现了CPU全部核心替换为自研泰山架构,从超大核到小核。而GPU方面也有其自研的马良系列。
▲华为麒麟9020芯片CPU内核情况,来源:极客湾Geekerwan
实际上,华为也是在麒麟9020这一代上才实现的完全核心模块自研,此前9010的CPU小核依然用的Arm公版IP。
在AI手机这波浪潮中,华为是手机行业中第一个将大模型能力用在手机上,实现自家智能助手升级的厂商,其自研麒麟芯片和自研鸿蒙操作系统的深度协同,让华为即使在工艺制程受限的情况下,每年也能稳定实现一定的整机性能提升,这对于AI体验的落地也十分关键。
相较于苹果华为这种“自产自销”的厂商,高通作为三方芯片厂商,其自研芯片的特性多少会一定程度上掣肘于安卓系统。
目前高通自研Oryon CPU已经迭代至第二代,并大规模量产应用在旗舰手机中,其自研的Adreno GPU也做了十几年。
Oryon CPU架构的突破,帮高通在CPU单核、多核性能上都领先于同代联发科旗舰SoC,在手机CPU能效方面稳居第一梯队。
高通自研的Hexagon NPU,最新一代AI算力突破了80TOPS,据称今年即将突破100TOPS,从算力绝对值层面来说,高通自研NPU有比较明显的优势。
联发科、小米的CPU、GPU核心模块都是基于Arm IP授权进行定制设计,均为Arm架构;三星的Exynos CPU虽然是Arm架构,但GPU却采用了AMD的RDNA 3架构。
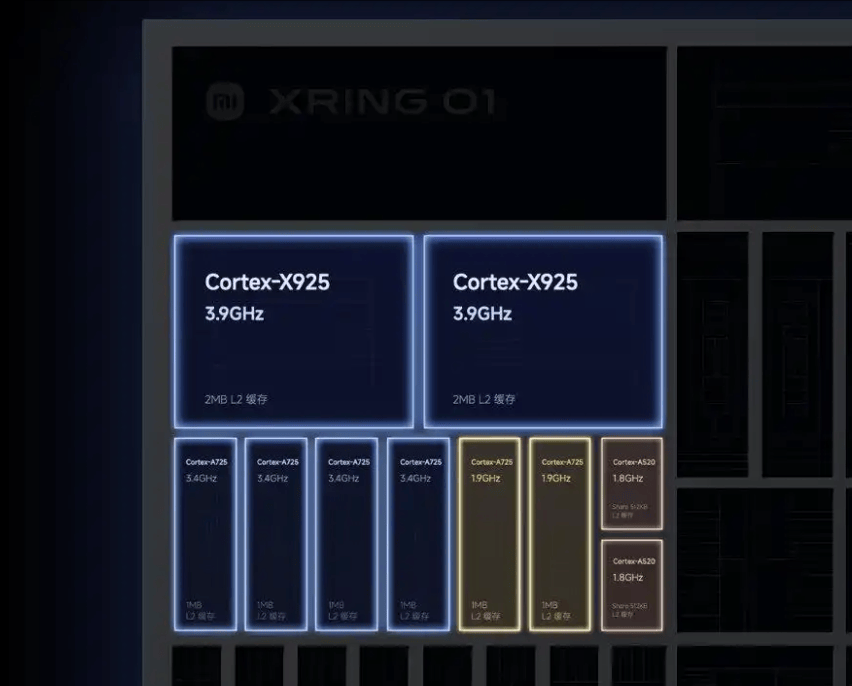
▲小米玄戒O1 CPU内核,来源:小米
ISP和NPU没有“公版”之说,因此各家都是自研定制,比如ISP方面联发科的Imagiq、小米的自研ISP;联发科旗舰芯NPU有42TOPS算力,小米也有自研6核NPU。
前段时间关于芯片“自研”的讨论成为科技圈第一大话题,实际上,正如前文所说,芯片自研与否与是否采用了Arm架构或Arm IP授权并无直接关系。
一个手机SoC里面包含上百个IP模块,如何让各个模块高效、低功耗地集成在一起,并保证其协同工作,还要实现差异化优势,这是真正的难点所在。
一位芯片行业人士告诉智东西,最难的不是“自研”,而是真正把芯片设计的每一个细节吃透,做出一个成熟好用、性能功耗平衡优秀的芯片,实际上,实现这件事的过程,就是在自研芯片。
可以看到,一方面,自研芯片核心技术可以直观地给产品带来性能或体验的优势,另一方面,芯片自研带来的不仅是芯片产品本身,更是对一家厂商整个技术版图的重要补全,对厂商优化芯片与操作系统、大模型、应用的协同都会有帮助。
不做深度自研,很难像苹果一样实现人无我有的优势,强化手机AI芯片自研技术,已经成为行业的必然方向。
三、都说苹果AI掉队了,怎么突然被苹果“反将一手”?
正如前文所说,如今早已不是“唯TOPS论”的时代,随着端侧AI快速发展,AI应用真正落地的能效表现成为行业关注焦点。
优秀模型一个接一个,但AI手机上的AI应用能否高效利用端侧AI大模型能力,如何在有限的能效内更高效地运行AI,最终实现好的AI体验,仍然存在很大优化空间。
在芯片本身过硬的基础上,手机AI芯片的相关开发加速工具支持完善程度也十分关键。
在这方面,苹果在今年WWDC上,迈出了非常关键的一步——向所有App开放权限,允许App直接访问苹果智能核心的设备端大语言模型。

如何访问?苹果发布了基础模型框架,也就是如今业内常常被讨论的苹果开源机器学习框架(MLX),让开发者可以使用苹果的模型,开发工具层面的App Intents则让开发者能在整个系统中关联自己App的内容和功能。
具体来看,苹果MLX支持Python、C++、C和Swift等多种主流编程语言,根据GitHub信息,其API对于开发者来说熟悉易用,同时支持函数变换的组合性、延迟计算模式、动态图构建、跨设备运行能力以及统一内存模型。
在性能方面,跟传统的机器学习框架相比,苹果MLX内存传输开销为零拷贝,同时对苹果芯片GPU计算能力进行了优化,未来MLX可以直接调用ANE专用指令集,而其他框架大多是间接支持或有限支持;动态图响应速度方面,MLX能达到毫秒级,PyTorch为秒级,TensorFlow则需分钟级。
对于开发者们来说,MLX的实时错误追踪比传统静态图框架快3-5倍,85%的NumPy/PyTorch代码可直接迁移,并且还可以利用苹果芯片统一架构减少跨平台适配工作。
可以说,苹果MLX是全流程的开源框架,从模型训练到推理的端侧优化,并且深度整合了自家的硬件。
安卓阵营中虽然没有能完全对标苹果MLX的开源机器学习框架,但在开发者提效降本方面也都发布了各自的软件平台或开发工具。安卓阵营的芯片厂商更多通过闭源SDK或开源协作的方式支持AI开发。
比如高通的AI软件栈,可以让开发者在手机上市几个月前,通过高通Device Cloud,基于骁龙8 Elite开发AI应用服务,进行调试、优化。AI应用可以通过ONNX、DirectML等框架和高通AI软件栈,实现NPU的加速。

▲高通AI软件栈
联发科这边则有天玑开发工具集(Dimensity Development Studio),比如其中的Neuron Studio能基于神经网络进行自动化调优,帮开发者进行跨模型的全链路分析,节省调优时间。
此外,联发科的天玑AI开发套件2.0,通过开源弹性架构提升开放度,模型库适配的模型数量提升了3.3倍,对DeepSeek这样的热门模型的关键技术实现端侧支持,提升tokens的生产速度。
总体来看,让AI芯片的能力可以被开发者高效地用到AI应用中,实现更好的端侧AI体验,这事目前仍然只有苹果做的是最完善的,安卓阵营并非不做,但生态层面的不统一、各自为战仍然会带来很大挑战。
结语:手机AI芯片之战,不能输的硬仗
在AI手机高歌猛进之下,手机AI芯片走到了舞台C位,成为巨头兵家必争之地。
虽然苹果看似在AI功能落地的“丰富度”上少了些惊艳感,但仔细梳理却能看到其AI功能端侧实现占比极高,其从底层芯片、操作系统到大模型、应用的打通,是安卓阵营极难段时间追赶的。
苹果AI诚然有其内部深层次问题,从团队到技术,但归根结底,苹果依然按照他最擅长的做法——小步快跑,来做AI,苹果确实在“架桥铺路”上花费了更多时间,但一旦打好地基,AI大厦的上限将充满巨大想象空间。
这也是安卓阵营从终端厂商到芯片厂商都不断加码芯片自研技术布局的重要性所在。真正好的端侧AI体验,离不开这些底层技术的支撑。
毫无疑问,AI的到来给手机芯片市场注入了新的活力,带来了新的变量,能否做出好的手机AI芯片将成为决胜AI手机之战的关键。