原创 嵌入模型:文本“已死”,多模态尚有红利,2025Q4科技观察
2025年Q4,上市公司Elastic对JinaAI的收购,
在掌声中落幕。
嵌入模型(Embedding)赛道的故事也降温了。
JinaAI是LLM时代的新秀,
在嵌入模型领域拥有成熟技术栈。
嵌入模型不是新玩意,
在AI基础设施领域,
是有一定历史的“常用组件”。
或者说,在AI理解世界方式的演进道路上,
“嵌入模型”这一组件不可或缺。
而Elastic公司,
则在荷兰阿姆斯特丹成立,
纽交所上市,
尤其擅长检索与日志分析软件,
Elastic当年虽然是搜索和AI基础设施公司,
但选择了更为传统和严格的纽交所,
体现它作为企业级基础设施厂商,
(比如Snowflake)的一种稳重定位。
从纯技术角度讲,是一家中间件平台,
Elastic收购的原因是啥?
看上去,中间件公司购买了AI新贵,
耳熟能详的答案是,
Elastic补齐其在模型,
工具链和开发者体验层面短板,
从而把产品链条做得更完整。
文本嵌入模型已趋于成熟,
成为AI基础设施的一部分。
在AI基础设施被云厂商通吃的周期里,
赶紧把"技术流量"转成“被收购的价值”实属正解。
在我看来,嵌入模型虽然不再是黄金极热赛道,
但它依然在产业里是螺丝钉般的存在。
文本向量化
(embedding,
文本经过嵌入模型后的向量表示过程),
正在演变成一种成熟的通用能力。

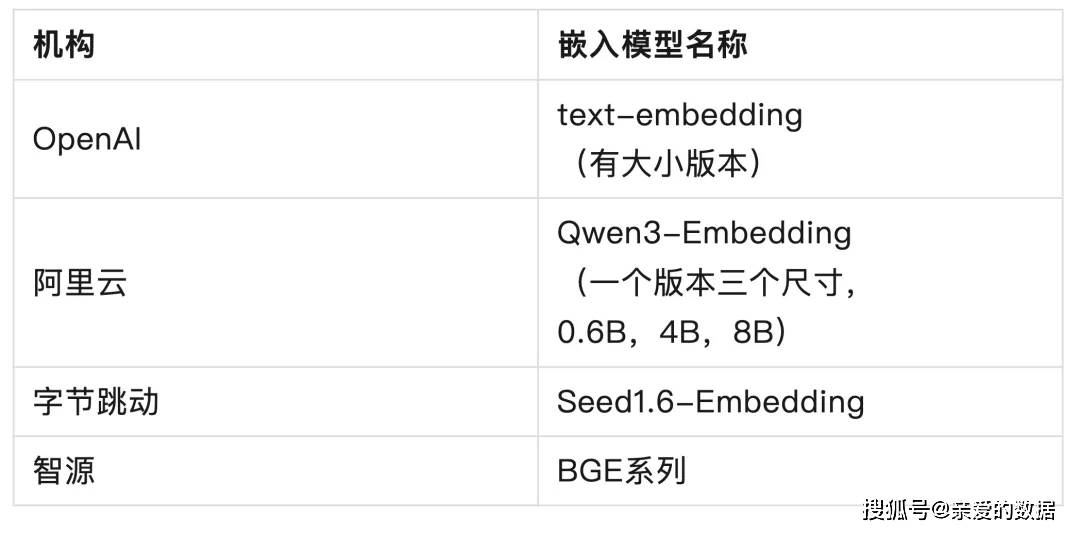
嵌入模型竞品不少,且开源,
不难发现,OpenAI、阿里Qwen头部公司几家,
都有嵌入模型,
不过OpenAI发布的最早,
可以追溯到 2022 年 12 月;
除了提高性能之外,一直发力于降成本;
也就是检索的成本越来越低。
嵌入模型越大,成本越高,
消耗更多的计算、内存和存储资源。
这里说嵌入模型大,
就是向量维度高的意思。
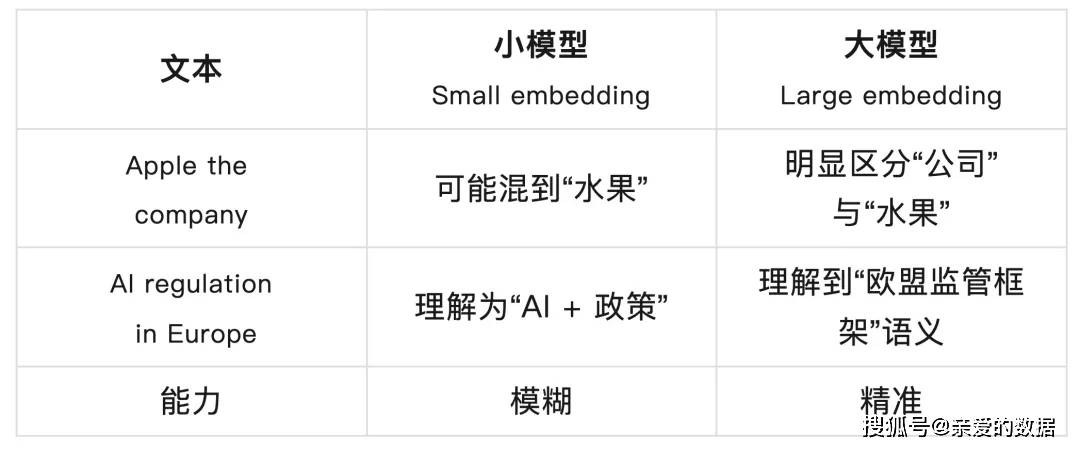
好比,
小是模糊照片,
看得快但细节少;
大是高清照片,
细节丰富但文件大。
要不要“开高清”,
取决于你想看多细。
我观察到的情况是:
观察一,
嵌入模型对大模型公司意味着什么呢?
头部大模型团队会顺手做一个,
简单说,只是"顺手礼包",不是战略高地。
那么嵌入模型还有什么玩头?
观察二,文本嵌入的门槛在被快速抹平。
几年前,“谁能把语义检索做顺滑”还算差异化,
但到今天,跑出一个能用的嵌入模型并不难。
开源模型、现成的训练脚本、乃至商用API,
足够让大多数团队低成本起步。
有技术小哥哥告诉我:
“BAAI General Embedding和JinaAI,
打得有来有回,他们就在这两款之间换着用,
哪个好用换哪个。”
我在智源有一个朋友,他告诉我,
BAAI General Embedding的主要技术骨干,
是一位低调大佬,
直接汇报给王仲远,
虽然我给他发了邮件,
但是为了不给猎头送炮弹,
本文不实名大佬名讳。
技术小哥哥们常说,
谁的开源新版本好,
就用谁的,何必买单?
这句闲谈的背后,
付费意愿随之蒸发。
嵌入模型很容易做好吗?
答案是否定的。

当答案是否定的,
这就得到了我的第三个观察,
嵌入模型:门槛虽低,做精不易。
现在的嵌入模型市场很清晰地分成两种:
入门级和企业级;
做出一个能用的,并不困难:
经验有且丰富,
我几年前写电商推荐系统(阿里和京东)的时候,
就写过类似组件。
我的理解是:
“嵌入模型就像是给语言拍‘X 光’——
它不生成句子,而是揭示“语义的形状”。
有了这些语义坐标,AI 才能真正知道,
哪两句话‘意思差不多’,
哪两篇文档‘八竿子打不着’。”
现在有开源用起来更爽。
入门级用于轻量级应用;
企业级适合复杂语义检索场景,
RAG 高质量高要求场景。

紫东太初多模态检索算法负责人,
高级算法经理郭海云博士,
她告诉“亲爱的数据”:
“嵌入模型更强调通用性,
而不是微调以契合特定业务域,
从创新研发技术上来说,
这个似乎不是难点了,
更多的是工程实现的巧妙权衡。”
类似技术重点包括,
如何在有限资源上保持泛化能力?
又如何将文本、表格、
图像、代码等多模态特征,
融合到一个稳定向量空间。
看上去,能否在这些工程化难题上长期交付,
还是要看团队技术水平。
另外,别忘了另一类需求:
是快速试点和中小团队落地。
这个需求,
基本上被JinaAI的开源模型很好地解决了。

问题来了,
JinaAI靠什么上岸?
它家的优势更准确地说是,
差异化,而非绝对领先。
具体来说:JinaAI在开源社区的传播力、
对开发者友好的工具链、
以及易上手组件的能力,
确实让它在快速试点和中小团队落地上具有优势。
这些特点是它的差异化,
也是Elastic有意收购或合作的逻辑所在。
相信大家也看出来了,
嵌入模型不是护城河,
是螺丝钉,
客户需求不同,
螺丝钉的型号就不同。
还有的客户关心:
成本能否压到可用水平?
索引更新能否实时跟上?
表格、图像、视频等非文本数据,
能否被统一纳入检索?
我找到了一位原大厂嵌入模型资深研发,
我认为,他来评价这件事足具资格,
原因是,
他是中国第一代大厂嵌入模型开源技术主力,
不仅如此,他的身份,
已经从技术转型为全栈产品经理,
也有自己的收费AI产品。
很可惜,他不愿意实名,
不过我相信,一些投资人能猜出来,圈子很小。
他告诉我:
“Embedding都我自己弄的,再用ONNX,
“把PyTorch框架上的模型编译成C++高速版”,
这样就能让BERT在CPU上飞起来。
他对比了在端上部署JinaAI的嵌入模型的情况,
对JinaAI的吐槽是:
JinaAI那些模型太大端上不适合。
其厂商官方还停留在“PyTorch”的原始时代,
自然被吐槽“又大又慢”。
他特意提到,他的方案,
比JinaAI(用Pytorch)推理效率高接近一倍。

嵌入模型有两种技术路线,
Istari企业智能创始人,
杨荟博士告诉我:
“嵌入模型的结构和LLM可以是一套
(比如LLM 架构去掉中间几层),
也可以不是一套的。”

一种是从 LLM 削出来的“Encoder子模型”。
另一种是专门为了相似度检索优化的模型,
或者说Encoder-only模型。
第二种技术路线的模型不依赖LLM,
而是独立训练的语义编码器,
结构上依然是Transformer,
但细节上做了很多“工程强化”。
嵌入模型要被下游的RAG消费,
或者说和RAG配合使用。
RAG流程有这样几个步骤:
1.把企业已有数据(文档、代码、FAQ、图像等)
预先做向量化,存进向量数据库。
2.查询阶段(实时)把用户输入的query转换成embedding,
3.用户问题和企业已有数据embedding在同一个向量空间里对齐。
4.把检索到的上下文就是“专有数据”补充给LLM。

这样一来,
大模型就能“理解”企业内部数据,
即使它原本没训练过这些文档。
如果你仔细观察,
会发现一个微妙的变化,
竞争已经转向多模态。
文本向量化的精度差异,
在很多场景里已经不足以形成强壁垒。
行业叙事的重心已经开始移动。
文本向量化的红利期正在结束:
模型趋同,生态成熟,增量创新有限。
嵌入模型是“找资料”的工具,
长上下文是“读资料”的范围。
多模态嵌入模型,
正在成为新的机会窗口。
又或者是不得不踢的加时赛。
把图像、音频、
视频、代码等复杂数据,
压缩进一个可用的语义空间,
并能被下游——RAG(检索增强生成)有效消费,
这才是2025年之后的真正战场。
谁能解决多模态的“粒度对齐”与“上下文整合”,
谁就能在下一个周期里拔得头筹。
整个行业往多模态方向上的加速被推动了。

RAG是业界当红解决方案,
也是嵌入模型消费的大头,
若RAG没前途,嵌入模型也没有前途了,
我观察到有如下行业观点的碰撞:

正方观点:
“模型长上下文能力的增长,
正在降低RAG的必要性。”
此方观点认为:
过去,大模型的上下文窗口有限,
RAG必须非常精准,
把“最有价值的(文档片段)”,
向量化后送给模型,
否则就放不下。
而如今,2M级上下文窗口已成为现实,
用户可以直接把长文输入模型,
绕过embedding,
也能获得不错的效果。
换句话说,embedding不再是“必须”,
而只是“可选”。
只要大模型能力一直增长,
只要OpenAI这样的企业一直投钱,
只要这场竞赛一直持续,
大于2M的上下文窗口需要用embedding吗?
或者换一种专业技术表达,
当上下文窗口超过 2M tokens 时,
模型是否仍需要通过嵌入模型生成语义向量,
以支持RAG?
当然,2M tokens≈3本《红楼梦》
当然embedding依然可以用。
原来就是很重要,
现在一些场景非必需了。
也就是说,
以前塞不下,
需要嵌入模型精准地“挑出”。
而现在上下文变长(2M+ token),
——可以塞更多候选资料进去,
对“精确召回”的要求没那么高,
嵌入模型的存在价值,
从“必需”变成“辅助”。
长上下文解决的是“能放多少信息”;
RAG解决的是,
“如何找到最相关的信息”。
也就是说,
长上下文削弱了对“高精度embedding检索”的刚需,在文本场景的“刚需属性”正在消解。
文本检索与大模型结合的护城河在坍塌。
坐拥1500+企业客户的Elastic,
其客户仍然有大数据量需求,
用嵌入模型作为一个工具没问题,
但它已经不是必备条件。
甚至部分产品已经完全绕开嵌入模型,
效果还要好。
嵌入模型在文本这里的红利期走到尽头,
但多模态数据还没有。
尤其是多种模态的数据,
无法直接用长上下文“硬塞”,
必须依赖这种手段,
文本的向量化正在成为成熟组件,
而多模态的向量化仍是行业必争之地。

反方观点上,
紫东太初多模态检索算法负责人,
高级算法经理郭海云博士,
告诉“亲爱的数据”:
“我不赞同上述说法。”
郭海云博士参与了,
紫东太初Taichu-mRAG框架的研发,
(通过统一多模态细粒度检索引擎,
与紫东太初多模态大模型协同,
实现了检索召回率,
和端到端问答准确率的双重提升)
她谈到,当前AGI有两大趋势,
会导致模型的长上下文需求越来越高,
RAG的需求并没有降低。
一个趋势是很多场景需要模型进行多模态推理,
推理中,思维链的生成,
会加剧模型输入上下文的长度增长,
另一个趋势是multi-agent技术的发展,
Agent的memory也会增加上下文的长度,
因为交互上下文就是memory的一部分。
尤其当前Agent落地的一大瓶颈就是上下文工程;
上下文太长,信息冗余,
长上下文也还没建模好,
上下文太短又信息不足,
所以需要检索技术精准找到最相关的上下文。
双方观点有分歧主要存在于,
RAG是否会因为大模型能力上涨而重要性下降,
但是,对于“多模态尚有红利”,
双方都没有争议。