剑指工业与物理AI:AMD锐龙AI嵌入式P100系列高端型号重磅登场
来源:电子工程世界(EEWorld)
AI、生成式AI正以前所未有的态势向边缘设备迁移,去APP化、本地化是当下AI发展的关键词,代理式AI、物理AI也在最近变得更加火热。从AIoT的初步探索,迈向真正意义上的边缘AI时代,这一转变让嵌入式行业发生着天翻地覆的巨变,也为嵌入式行业带来巨大的机遇。
提起AMD,很多人的往往会先想起来它的PC和服务器业务,事实上,嵌入式业务和边缘AI也是AMD的重要一环,也可以说是AMD业务的第三大支柱。
目前,在嵌入式领域,AMD拥有两条关键产品线:一个是AMD锐龙AI嵌入式处理器(Ryzen AI Embedded),另一个则是AMD EPYC嵌入式处理器。
1月,AMD推出4~6核的锐龙AI嵌入式P100系列,面向沉浸式显示和汽车应用。今天,AMD继续扩展P100系列,推出8~12核的高端型号产品,专为工业自动化、医疗设备、机器人技术等需要平衡计算、图形与AI性能的混合负载场景而设计。此外,本次也预告最多支持16个Zen 5核心的X100系列将于今年下半年上市。
据贝哲斯咨询预测,至2030年全球边缘人工智能(AI)芯片市场规模将达到3747.45亿元。由此可见,AMD所面临的市场空间十分广阔,随着新产品的推出,其在行业内的市场地位也将持续提升。
工业、医疗、机器人,催生嵌入式性能升级
人工智能的落地场景正经历显著迁移:它不再局限于云端数据中心或消费级应用,而是加速渗透至工业现场。随着工业自动化系统日益复杂,对实时数据处理与边缘端机器学习能力的要求持续攀升,硬件架构也必须同步演进以满足严苛的工况需求。
根据AMD锐龙嵌入式处理器高级产品市场经理Ioseph Martinez的分享,目前,有三个边缘AI场景正在发生变革:
一是工业场景,制造商正从过去功能单一的专用设备,逐步转向集成机器视觉、AI算法、控制逻辑与数据分析于一体的融合系统,以支撑生产线上的实时决策;二是医疗设备领域,同样呈现类似趋势,AI正被嵌入具备高精度成像与临床推理能力的终端系统中;三是机器人领域,依托物理AI技术的普及而加速走向产业化,推动感知、导航与决策能力在物理世界中实现闭环。
上述多重动因共同催生了对可扩展计算平台、AI加速芯片及嵌入式系统架构的强劲需求,因此,AMD再次进一步扩展P100系列产品的计算性能。
将可扩展计算能力放在一颗芯片上
“锐龙AI嵌入式P100系列将强劲的可扩展计算能力集成在一颗x86 SoC芯片上,它同时提供了CPU实时控制性能,以及GPU和NPU的图形与AI加速能力。最关键的是,它采用了AMD最新的Zen、RDNA和XDNA架构,让CPU、GPU和NPU在性能和能效上都达到顶尖水平,实现了异构计算的出色平衡。”Ioseph Martinez介绍道。
最新的8~12核P100最低功耗可至15W,与低核心数的P100保持相同的封装尺寸,并且能够全天候运行,具备长达十年的使用寿命。

从具体规格来看,P100提供支持工业级温度、标准温度和扩展温度的不同选项,系统性能随不同选项扩展,所有选项均具有通用的I/O和封装,构成了一个真正可扩展的产品系列。所有器件都针对15至54W的功耗范围进行了调优,使OEM能够根据图形、安全控制和各类应用的需求进行扩展。
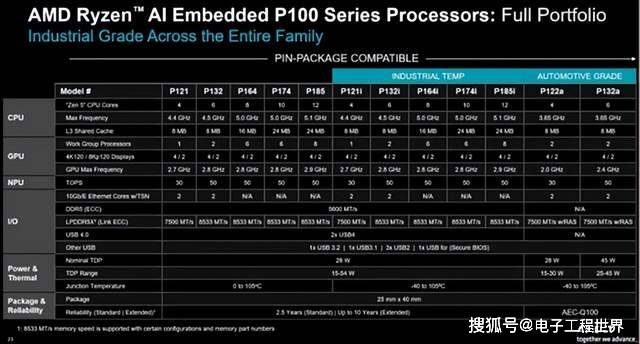
由于所有核心采用统一的指令集架构,P100的软件的扩展和移植变得容易。Ioseph Martinez对此介绍:“我们与客户沟通时,他们最优先考虑的一点是可扩展性。这意味着一种架构能够支持不同的应用和核心数量,P100系列即可从4核扩展到12核。客户能够保护其软件投资,并在通用硬件平台上构建完整的产品线。CPU核心数量均衡扩展,同时GPU计算能力逐步提升,以支持更高级的图形和AI应用。其结果是提供了一个可扩展的基础,让客户能够构建满足不同功耗和性能层级的产品线。”
CPU、GPU、NPU,三类算力的有机结合
AI时代,如果想要最高效地计算,CPU、GPU、NPU三大算力引擎的紧密耦合和相互协同必不可少。P100架构则在CPU、GPU和NPU之间实现了平衡,三者共同将合适的工作负载分配到同一器件上合适的引擎,从而优化功耗、延迟和占用空间。
P100的组合中每个器件的核心都是基于4nm制程工艺的单片式异构架构。此外,P100的统一微架构,结合虚拟化和分区支持,实现了确定性的工作负载隔离。因此,即使在重负载下,关键功能也能保持受保护状态。

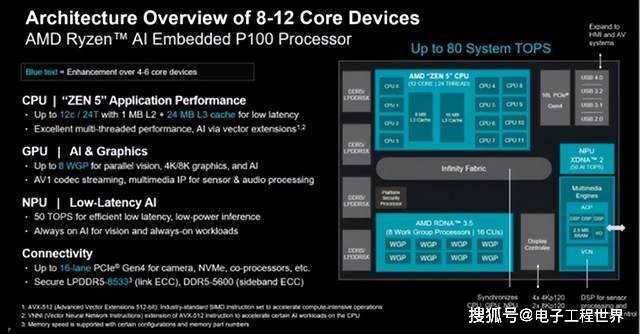
首先,Zen 5 CPU提供了可扩展的x86每瓦性能。CPU可扩展至12核心和24线程,有效将小型P100器件的核心数翻倍,并增加了L3缓存以减少延迟。多线程性能是Zen 5的核心优势之一,P185提供了高达39%的多线程性能提升,这在同时运行多个实时服务时至关重要。这一优势意味着控制回路和应用服务可以同时运行,而不会牺牲响应能力。

其次,RDNA 3.5 GPU支持视觉、图形和AI加速。P100提供了显著更多的GPU计算单元,用于更复杂的显示渲染和AI任务。

与此前推出的低核心数P100相比,全新的P100的GPU单元最多可提升8倍,图形性能实现飞跃,从沉浸式数字应用场景跃升至真正的广播级渲染,可获得多达4路4KP120显示输出,用于高端成像和LED显示屏。集成的AV1解码器和AMD视频引擎IP能够在边缘端提供高保真流媒体传输,且不增加GPU负担。

最后,XDNA 2 NPU提供常开、低功耗的推理能力,相比GPU功耗更低、延迟更低。P100整个系列的NPU保持一致,提供总计50 TOPS的算力,使得整个系统最高可达80 TOPS。
所有三个引擎都具备AI能力,CPU通过向量扩展支持特定的AI工作负载。对于需要大内存的模型,如大语言模型,带宽变得至关重要。LPDDR5内存提供了所需的吞吐量,确保GPU和NPU数据供应充足,减少停顿,维持高性能。
iGPU、NPU,合理分配负载最重要
“AI加速的核心在于将合适的工作负载分配给合适的引擎。”Ioseph Martinez表示, iGPU最适合处理突发性或事件驱动型工作负载,例如当事件触发时启动的大模型推理或复杂的场景理解。NPU则针对常开AI进行了优化,例如必须低功耗运行并具有确定性延迟的持续目标检测或后台安全监控。两者也可以协同工作:NPU可以处理前端会话和过滤,而iGPU则接管进行更深度的分析或高阶推理。

iGPU和NPU各自拥有针对性能和功耗优化的专用软件环境:GPU由ROCm支持,而NPU由Ryzen AI软件支持。两种环境共享基于PyTorch、TensorFlow和ONNX等框架构建的公共基础。客户可以使用iGPU和易于上手的ROCm库开始开发。随着开发的深入,可以探索结合两个引擎的优化方案。
很多人可能从数据中心和HPC领域了解到ROCm,现在它已可用于嵌入式iGPU。ROCm是AMD的开放软件栈,使用开放的编译器、运行时和库来运行标准AI框架,使开发者能够在不改变工作流程的情况下,从云端迁移到边缘端。
关键是HIP(Heterogeneous-computing Interface for Portability),它将GPU编程与硬件解耦,避免了供应商锁定,允许移植现有的GPU代码,包括基于CUDA的项目,而无需从头开始。
AMD正在将经过生产验证的软件栈引入嵌入式领域。ROCm for Embedded旨在降低开发门槛,开发者可直接使用PyTorch等主流框架,选择AMD iGPU作为后端运行模型,并可即时调用适用于视觉、多模态 AI 及行动管线的嵌入式优化模型。
对于从CUDA迁移的用户,HIP提供了近乎即插即用的支持,通常仅需极少量代码修改即可完成移植。多数开发者可在框架层面完成开发,同时系统也开放内核与C级优化接口,支持在必要时进一步挖掘性能潜力。

落到实地场景中
Ioseph Martinez介绍,8~12核P100主要面向广阔的工业市场,在工业自动化领域,AI主要用于视觉驱动的检测和缺陷识别,结合预测性维护以优化流程;在机器人技术领域,物理AI涉及视觉、运动控制和大语言模型风格的推理的交汇,因此需要x86平台的协调、集成AI和隔离能力;在医疗健康领域,它将高级成像与设备端AI相结合,用于3D重建和分割技术的超声和内窥镜检查,也可用于医疗大语言模型支持结构化的临床报告生成;在专业音视频领域,P100强大的图形能力支持LED显示屏和广播设备。
“这些都是当今最先进的工作流程,AMD通过x86和FPGA早已深度布局这些市场。”那么,P100究竟具体如何应用到目标市场?Ioseph Martinez通过几个实例具体介绍了这款产品。
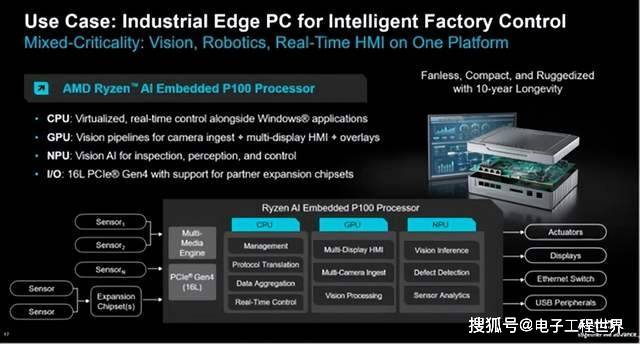
在现代工厂中,AMD正将PLC、机器视觉和HMI整合到一台工业PC中。在P100中,NPU执行实时的缺陷和异常检测,CPU解释结果并触发执行器,GPU则提供可靠的、带有摄像头画面叠加的多屏HMI仪表板。通过从4核到12核的可扩展产品组合,可以扩展到支持更多摄像头、传感器、机械臂和网络功能。
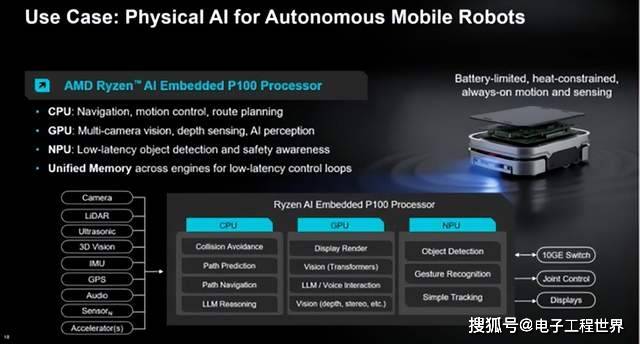
随着工厂复杂性增加,自主移动机器人需要实时导航、多传感器感知和持续的安全监控。在P100上,CPU处理导航、运动控制和路径规划;GPU处理多摄像头视觉和深度感知,以理解环境;NPU则以低功耗运行常开的目标检测和安全感知。引擎间的统一内存保持了闭环控制的低延迟。
在超声设备中,P100实现波束形成、成像、AI都在单一器件上运行,CPU从前端捕获原始数据,并管理系统控制和网络连接;GPU执行波束形成、图像重建、渲染和基于AI的增强;NPU卸载AI推理任务(如异常检测),同时加速关键信号处理。其结果是构建了一个集成了AI的紧凑系统,无需独立GPU,从而降低了延迟和系统复杂性。

越来越多伙伴加入到锐龙AI嵌入式P100系列
根据Ioseph Martinez介绍,目前芯片现已开始提供样品,并已送达客户手中,预计2026Q3投入生产;CPU、GPU和NPU的完整工具现已发布,未来两年每个季度都会增加新功能;2026年下半年将开始提供客户参考板;针对特定合作项目,AMD构建的客户参考板将于下半年推出,该板集成了完整的PCIe、USB、显示、内存和调试接口,可加速产品启动。
Ioseph Martinez强调,对于量产开发板,AMD已经拥有强大的ODM合作伙伴支持,研华、康佳特和控创正在展示基于6核P100的平台,更高核心数的平台也即将推出。这仅仅是个开始,凌华科技、华擎、瑞传科技、艾讯、广积科技、蓝宝科技等更多伙伴也正在加入。