原创 国产AI芯片跑出加速度!大摩最新预测:自给率4年后将达76%!
近日摩根士丹利发了一份关于中国AI GPU的报告,里面的预测数据可以说是相当有料。
根据他们的测算,到2030年,咱们国家AI GPU芯片的自给率将从2024年的33%一口气飙升到76%。
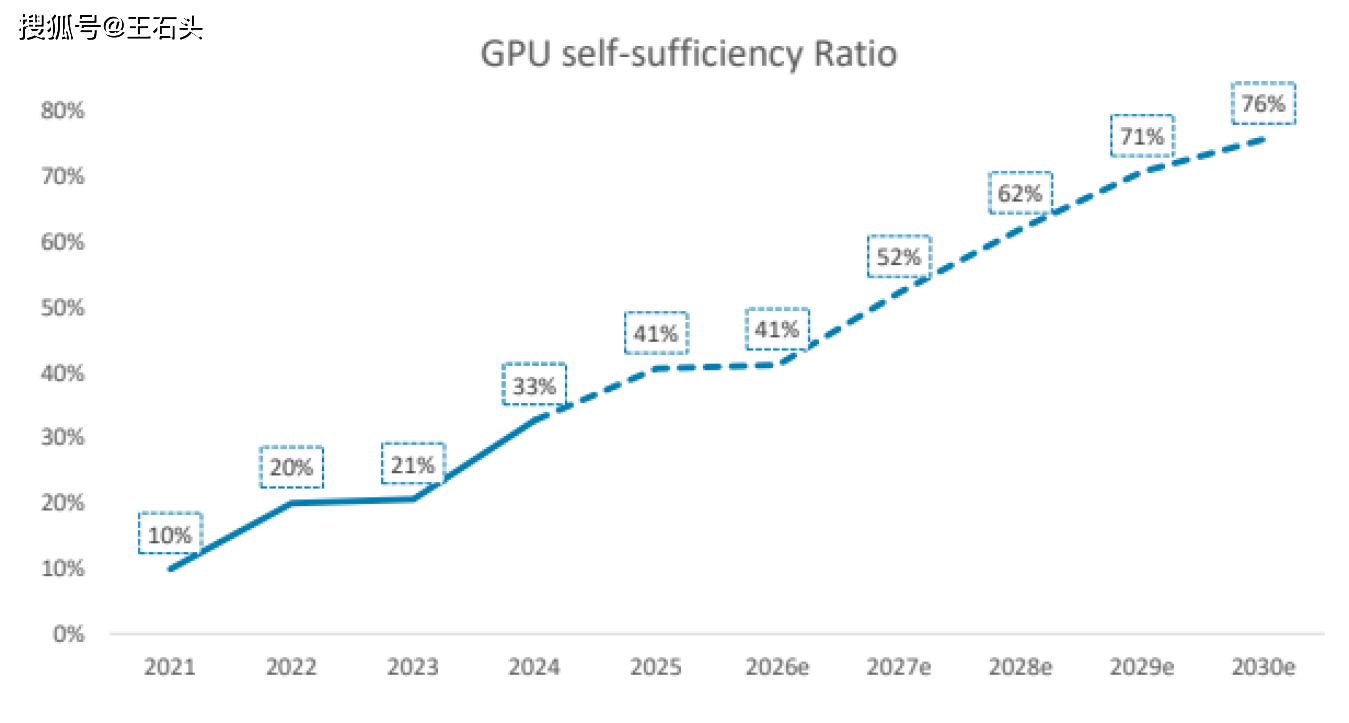
简单来说,就是六七年之后,咱们手里用的AI算力,每4块钱的芯片支出里,有超过3块钱是花在国内芯片上的。
这个转变速度,说实话比很多人预想的要快得多。
大摩这份报告里给了一组非常具体的产能预测数据。2025年国内12纳米以下先进工艺的月产能大概在8000片左右。
这个数字看着不大,后面的增长曲线是陡峭的,到2027年要翻到20000片,到2028年直接跳到42000片。
最关键的是,大摩认为到了2028年这个节点,这些产能就可以满足核心的自主需求了。
再到2030年,进一步增加到50000片,而且良率预计能爬升到50%。

为什么要强调良率到50%?懂行的朋友都知道,芯片制造这玩意儿,良率就是生命线。
从30%到50%的跨越,意味着单位成本的大幅下降,也意味着从能做出来到能做好、能做赚钱的质变。
虽然在极尖端的制程上,我们和美国确实还有差距。但大摩这份报告还点出了一个非常关键的策略,叫做以规模补工艺。
什么意思呢?就是既然在单点技术上暂时追不上最顶尖的,那咱们就在整个产业链上铺规模,扩大晶圆厂、扩产设备、扩充产能。
这种打法虽然听着有点笨,但效果很扎实,你有最锋利的针,但我有成捆的针,而且我还能不断优化怎么用这些针,最后谁的产出多、谁的性价比高,还真不一定。
当然,如果只看产能数字,可能还只是量的层面。但大摩这次分析里最有意思的一个观点,是关于成本的。

报告指出,中国AI数据中心的总拥有成本非常有竞争力。这背后有几个支撑点。
第一,芯片采购价格本身就比海外大厂的低;
第二,咱们的电力成本有优势,尤其是在西部那些绿电丰富的地方;
第三,整个算力基础设施越来越完善,像东数西算这种大工程,不是光建几个机房,而是把算力网络盘活了。
另外大摩在报告里说了一句话:在推理领域,每Token成本要比极致性能更关键。
什么叫推理?就是模型训练好了之后,真正拿出来用的时候,像ChatGPT给你回答问题,那一下就是推理。
现在AI正在从技术验证走向规模应用,推理的算力需求占比越来越高。有预测说,到2026年推理算力可能要占到整体AI算力的六成以上。
在这个阶段,用户关心的是我用这个AI服务贵不贵、快不快,而不是训练这个模型的时候用了多厉害的卡。
这时候,每Token成本就成了核心竞争力。Token是啥?你可以简单理解为AI处理信息的最小单位。你问一个问题,模型回答一段话,这里面消耗的就是Token。

现在国内企业在这个赛道上卷得挺狠的。
有公司和国产GPU厂商合作,推出了百万Token一分钱的推理成本计划;还有厂商直接把推理成本干到了1块钱每百万Token。
这意味着以后用AI可能真的像用水用电一样便宜。当成本低到可以忽略不计的时候,AI才能从奢侈品变成日用品。
当然,大摩这份报告也不是光说好话。他们特别强调了一点,政策可以加速早期发展,但长期价值取决于商业竞争力。
也就是说,靠补贴、靠政策支持,可以把产业先做起来,但到了2028年之后,国产AI GPU供应商能不能继续增长,得看能不能真正证明自己的经济效益。
如果只是能用,但用起来不划算,那市场还是会用脚投票。
他们做了两个情景假设,乐观的话,国产GPU不仅能做推理,还能拓展到训练领域,甚至可能被海外客户采用。
悲观的话,如果差异化优势消退,那可能就会进入同质化竞争和行业整合的阶段。

总的来看,大摩这份报告给国产芯片画了一张很清晰的路线图,未来几年,产能爬坡是确定的,成本优势是明牌,推理市场是突破口。
到2030年76%的自给率,不是一个凭空吹出来的数字,背后是晶圆厂一座座建起来、良率一点点提起来、成本一寸寸降下来的实打实功夫。
当然,路还长,挑战还多,但方向对了,就不怕路远。